Over the holidays I often enjoy learning a new data-structure by implementing it. This year is no different, and so I implemented a Trie (pronounced "try").
http://en.wikipedia.org/wiki/Trie
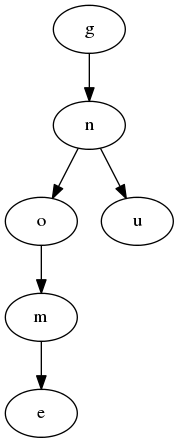
A Trie is a tree structure where each node of the tree contains a single character from an inserted string key. The first character of the string key is in the root node, and the second in a child, and so forth until you reach the end of the string key. Each node can point to multiple children and therefore the prefix of similar strings share nodes in the tree.
In the example this is illustrated with the two string keys "gnome" and "gnu".
A trie is a useful data-structure when you have a very large data set of keys you would like to search through for a particular key. Each node you traverse in the tree gets you closer to your target string. However, one fantastic addition is that it allows you to find all of the other strings keys sharing this prefix without looking at the strings that do not.
For example, if I wanted to see all of the strings that started with "gn", I would get the results "gnome" and "gnu" based on the above example.
So I set out to build one of these for myself. However, I wanted to add a twist on it. I wanted to try to make a variant of the data-structure that fit well into the cache-line of my computer.
A cache-line is a short run of data that your CPU can access in the L1 cache. On most (all?) x86_64 machines, this is 64 contiguous bytes. Every time you access main memory, the CPU accesses the run of 64 bytes that contains your target memory address and loads that into the CPU. Therefore, if you can optimize your data-structure to align with these cache-lines, you can get a good performance boost!
To build this data-structure, we need a couple of things. We know that it is a tree-like structure, so nodes will be required. We know that we need to have key/value pairs, so we need a place to store a pointer to the value provided with each string key. We know that we need pointers to the children nodes because this is a tree (and I learned that a pointer to the parent is also quite useful).
Additionally, since I plan to align these to cachelines, we need the ability to allocate more memory for more keys as they are added to each node.
I took a novel approach using dynamically sized structures. This allowed me to design each structure to be exactly one cacheline on x86_64. But since we need to be able to grow as more children are added to a node, the node also serves as the head to a linked-list. Each chunk in the link list contains a small array for up to 6 keys, up to 6 pointers to children nodes (saving a little space for overhead), and a pointer to the next chunk in the linked-list.
struct _TrieNode
{
TrieNode *parent;
gpointer value;
TrieNodeChunk chunk;
};
struct _TrieNodeChunk
{
guint8 flags;
guint8 count;
guint8 keys[6];
TrieNodeChunk *next;
TrieNode *children[0];
};
By making the chunk a dynamically sized struct, I can place it inside of the node (sacrificing two pointers) and still fit four. That is pretty good considering it also buys me one less allocation and better cache locality when following pointers from the parent nodes.
I read a paper recently that mentioned that "move-to-front" can significantly raise your "cache-hit" ratio for L1 cache. A "cache-hit" is when your CPU needs to access a piece of memory and it is already in the L1 cache (meaning you do not need to fetch it from main memory). So I decided to do this for mine as well.
Move-to-Front moves a key that was just accessed to the first key in its containing node. It turns out that many workloads end up accessing the same node multiple times. Therefore, having that data embedded in the target node results in very large improvement in lookups, inserts, and removals per second!

In the use case I was working on, lookups took only 40% of the original elapsed time! Inserts and and removals were also quite dramatic, both taking about 70% of the original elapsed time. I attribute the difference between the lookup case and the insertion/delete case to malloc and free overhead.
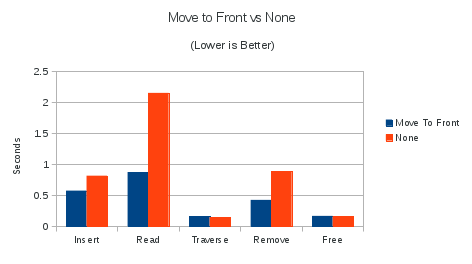
Above test is for testtriegauntlet located here.
I started by using plain old gmalloc0() and gfree(). (I'm still using those now, actually). But I wanted to see how I could change the allocator to improve the performance of the data structure.
Since we are doing almost exclusively 64-byte allocations, this seems like a perfect problem for the GSlice allocator (a SLAB based allocator that keeps around free'd memory to re-use for structures of the same size). However, that ended up being a lot slower. Perhaps that had to do with the attempt to be lock-free in some cases, and therefore flushing the cachelines that I'm working so hard to keep full with relevant data.
Bummer.
Next up, manage my own linked-list of free'd memory and re-use that instead of calling g_malloc0(). Additionally, I can allocate in one big chunk a few thousand structures at a time (and even more importantly, memset() them to zero in a single call).
Another Big Win!
One of the interesting comparisons for this test was to see if auto-completion for a source editor widget could be faster with a Trie as compared to a string array. If you have an unsorted string array you must scan through all strings to find matching prefixes. Otherwise you can binary search them (and then walk the array until you find a string that does not match the prefix).
When using unsorted string arrays and my sample set of about 16,000 function symbols, the searching the string array was faster for up to 3-4 characters.
Once you have reached about 5 characters, the Trie would be faster. The neat property of the Trie is that the more input you provide it, the faster it gets. So by time you are about 10-15 characters deep in your symbol name, the amount of time it takes to run is close to irrelevant (for my use case).
Make it sorted, and binary search it for matching prefixes (and then walk until you get input that does not share the prefix).
In not sure either the Trie or the String Array provide quite what I'm looking for yet. I've found that tab-completion in bash is what most people are familiar with when it comes to completion. So providing a similar experience might be in my best interest. For those unfamiliar, the experience is one that when you press TAB, the completion is provided up to the next character that can provide disambiguation.
I'm considering the idea of using a string array up to a certain number of characters and then the Trie after that, but I'm not sure its worth the doubling of memory overhead. Both data-structures could be mmap()d however (in fact some CTags completion providers do this). On one hand, the Trie could give me a pointer to symbol information (like docs, parameters, etc), but a string array could do the same with a second array).
A pretty clear win would be to merge nodes with a single child into one node so that instead of having one character key in the node you could have a couple characters of the key in a node. This would move more into the realm of a Radix tree.
So I guess it requires further science. I'll likely follow up at a later time as I play with this more.
-- Christian Hergert 2012-12-31